
Blog / GDPR Compliance: Role of Anonymization and Pseudonymization
GDPR Compliance: Role of Anonymization and Pseudonymization
GDPR compliance is crucial for any business handling EU residents' data - even those based outside the EU, like in the UAE. Two key techniques, anonymization and pseudonymization, help businesses meet GDPR standards while safeguarding personal data.
- Anonymization: Irreversibly removes personal identifiers, exempting data from GDPR rules.
- Pseudonymization: Replaces identifiers with tokens or encryption but retains re-identification potential, keeping data under GDPR.
Both methods support secure data use for analytics, marketing, and operations while mitigating risks. UAE businesses, especially in sectors like hospitality and retail, must adopt these techniques to avoid penalties and ensure smooth cross-border operations.
Key Takeaways:
- Anonymization is ideal for trend reporting and benchmarking.
- Pseudonymization allows detailed analysis and personalization but requires strict controls.
- Secure handling, encryption, and role-based access are essential for compliance.
These practices align with GDPR's "Privacy by Design" principles and help protect customer trust while enabling data-driven insights.
Legal Requirements Under GDPR
Relevant GDPR Articles
The GDPR outlines key privacy principles, including the definition of personal data (Article 4(1)) and pseudonymisation (Article 4(5)). It also introduces the concept of privacy by design (Article 25) and requires data controllers to implement security measures appropriate to the level of risk involved (Article 32).
Recital 26 provides clarity on anonymisation standards, stating that data is only considered anonymised when individuals cannot be identified using any method that is reasonably likely to be employed. This evaluation takes into account factors like cost, time, available technology, and accessible datasets. If there’s any possibility of re-identification, the data remains pseudonymised and is still governed by GDPR.
European Data Protection Board Guidelines
The European Data Protection Board (EDPB) issued its 2025 Guidelines, which describe a three-step approach to pseudonymisation: removing identifiable markers from the data, storing re-identification keys separately, and applying encryption with strict access controls.
The Guidelines highlight the importance of keeping pseudonymised data and re-identification keys apart. They also stress that pseudonymisation must be assessed within the specific context of its use, ensuring its effectiveness against plausible risks. While pseudonymisation is recognised as a useful technique for protecting privacy and enabling lawful secondary uses - such as analytics and AI model training - it does not exempt the data from GDPR. Individuals retain their rights over such data. These standards provide a framework for understanding GDPR’s reach and implications, even outside Europe.
Impact on UAE Businesses
UAE-based organisations that target or monitor individuals in the EU are required to comply with GDPR (Article 3). This makes pseudonymisation and anonymisation critical tools for managing cross-border compliance risks.
For UAE businesses, handling personal data from EU residents - whether through online bookings, loyalty programmes, website analytics, or property-related inquiries - requires adherence to GDPR’s safeguards outlined in Articles 25 and 32. Techniques like pseudonymisation and anonymisation can help reduce compliance risks and limit liability in the event of a data breach. This is particularly important when dealing with cross-border data transfers for purposes like analytics, profiling, or marketing.
To meet these obligations, UAE data controllers should ensure their data processing agreements with vendors specify the following:
- Which data fields must be pseudonymised or anonymised.
- The methods to be used, such as encryption or tokenisation.
- Secure handling and storage protocols for re-identification keys.
Anonymization and Pseudonymization under GDPR
Anonymisation vs Pseudonymisation
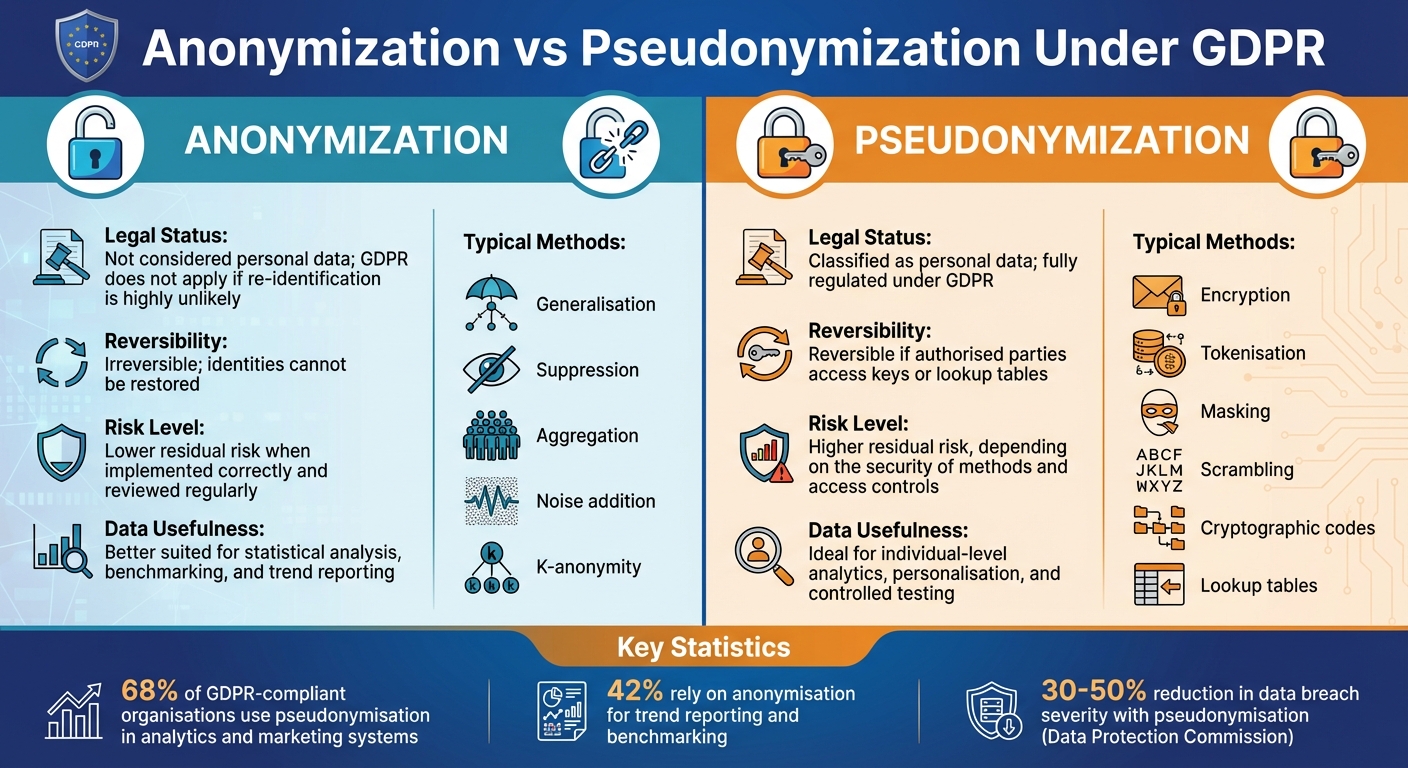
GDPR Anonymization vs Pseudonymization: Key Differences and Methods
Legal Status Differences
When it comes to compliance with GDPR, anonymised and pseudonymised data fall into distinct categories. Anonymised data, which has been processed to ensure individuals cannot be identified, is no longer considered personal data under GDPR. This means organisations handling anonymised data are exempt from obligations such as responding to data subject requests, adhering to retention rules, or navigating cross-border data transfer restrictions.
On the flip side, pseudonymised data still qualifies as personal data under GDPR. Even though direct identifiers are replaced with tokens or encrypted values, the data can potentially be traced back to individuals if someone gains access to cryptographic keys or lookup tables. As a result, organisations must comply with all GDPR requirements, including having a lawful basis for processing, maintaining transparency, and implementing strong security measures.
Methods and Risk Levels
The methods and associated risks of anonymisation and pseudonymisation also differ significantly. Anonymisation relies on techniques that permanently reduce the likelihood of identifying individuals. Common practices include:
- Generalisation: Simplifying data by converting specific details (e.g., exact birth dates) into broader categories like age ranges or reducing precise addresses to city-level information.
- Suppression: Removing unique data combinations that could reveal an individual's identity.
- Aggregation: Reporting group-level data, such as "1,000 customers in Dubai purchased product X", instead of individual records.
While these methods reduce the risk of re-identification, they also limit the data's usefulness for detailed analysis or personal insights.
Pseudonymisation, however, uses reversible techniques to obscure identities while preserving much of the data's utility. Popular methods include:
- Encryption: Applying cryptographic algorithms to transform data into unreadable formats, particularly useful for datasets that aren’t frequently shared.
- Tokenisation: Replacing sensitive values with random strings of characters, often used for structured data like customer IDs or payment details.
- Data Masking: Obscuring specific data elements to protect sensitive information during processing.
These techniques are advantageous for analytics and personalisation but come with a higher risk. If cryptographic keys or lookup mechanisms are compromised, re-identification becomes possible.
Side-by-Side Comparison
Here’s a quick look at the key differences:
| Dimension | Anonymisation | Pseudonymisation |
|---|---|---|
| Legal status (GDPR) | Not considered personal data; GDPR does not apply if re-identification is highly unlikely | Classified as personal data; fully regulated under GDPR |
| Reversibility | Irreversible; identities cannot be restored | Reversible if authorised parties access keys or lookup tables |
| Risk level | Lower residual risk when implemented correctly and reviewed regularly | Higher residual risk, depending on the security of methods and access controls |
| Data usefulness | Better suited for statistical analysis, benchmarking, and trend reporting | Ideal for individual-level analytics, personalisation, and controlled testing |
| Typical methods | Generalisation, suppression, aggregation, noise addition, k-anonymity | Encryption, tokenisation, masking, scrambling, cryptographic codes, lookup tables |
sbb-itb-058f46d
How to Apply These Techniques
Pseudonymisation Methods
To effectively pseudonymise customer data, start by mapping out where your data is stored - across CRM systems, marketing automation platforms, analytics tools, and advertising channels. Then, categorise each field as either a direct or quasi-identifier. Once you’ve done that, select the best pseudonymisation technique for each category.
For direct identifiers like email addresses or customer IDs, tokenisation works well. This involves replacing sensitive data with randomly generated tokens stored in a secure lookup table. Tokenisation supports tasks like omnichannel tracking, frequency capping in campaigns, and identity resolution across systems - all while keeping the original data separate and secure. For example, Wick's CDP implementation for Baladna successfully unified customer insights across channels while safeguarding over 1 million data points.
For fields requiring potential recovery - such as customer service notes, addresses, or financial details in AED - encryption is a solid choice. Use cryptographic algorithms like AES, and store encryption keys separately from the data under stringent access controls.
When you only need consistent matching (e.g., for deduplication, syncing custom audiences, or identity stitching), hashing with salt is a reliable option. Adding a salt to your hashes reduces the risk of brute-force attacks, and since decryption isn’t necessary, it keeps the process secure and streamlined.
A critical step in pseudonymisation is separating the “secrets” (tokens, keys, etc.) from the processed data. Ideally, this should happen right at the point of data ingestion. For instance, an API gateway could tokenise email addresses before they even reach your analytics layer, ensuring that downstream tools only handle pseudonymised identifiers.
Anonymisation Methods
When traceability isn’t required, anonymisation offers a way to process data while staying compliant with privacy regulations like GDPR. A common method is aggregation: grouping data into cohorts - by emirate, campaign, segment, or channel - and removing the ability to identify individuals. To ensure privacy, enforce minimum group sizes (e.g., suppress data for groups with fewer than 10 customers). This approach is particularly effective for reporting metrics like revenue in AED, conversion rates, and funnel performance while adhering to GDPR’s data minimisation principles.
Another technique is noise addition, where controlled random variations are introduced into metrics. For example, adding or subtracting a small percentage from counts or revenue values can protect small segments from re-identification while maintaining overall trends.
For more advanced needs, synthetic data generation is an option. This involves training models on pseudonymised data to create synthetic datasets that mirror the statistical properties of the original data without containing real individual records. This is especially useful for testing new CDP features, building BI dashboards, or training AI personalisation tools without exposing sensitive customer details.
To implement these methods, use your data warehouse or analytics layer. Build ETL jobs that transform event-level logs into daily or hourly aggregates, removing all direct identifiers and pseudonymous markers in the process. Privacy thresholds can be enforced in SQL views, where small groups trigger "insufficient data" messages. Noise can also be applied during queries or via materialised views, fine-tuned to balance privacy with decision-making accuracy.
Both techniques require strict security protocols to ensure data integrity.
Security and Access Controls
Strong security measures are essential for both pseudonymisation and anonymisation. Access to pseudonymisation secrets, such as tokens or encryption keys, should be limited to authorised personnel - typically security, compliance, or designated customer service teams. Implement role-based access controls, multi-factor authentication, and comprehensive audit logs to monitor activity.
System design should prioritise decentralised storage. For example, keep keys and lookup tables in separate locations - ideally in different cloud regions or on-premises vaults. This separation ensures that even if one system is breached, re-identification remains nearly impossible.
Automation is another key element. Automating these processes reduces the risk of human error and ensures consistency. Regular risk assessments are crucial too. The EDPB’s 2025 Guidelines on pseudonymisation emphasise the importance of evaluating measures against emerging re-identification techniques and evolving data combinations. Keep detailed records of your processing activities and conduct periodic data protection impact assessments, as required by Recital 26’s "reasonably likely" re-identification test.
For UAE organisations handling data from EU subjects - such as European tourists or remote clients - ensure that your controls align across time zones and cloud regions. This helps maintain GDPR compliance while meeting local operational requirements, ensuring your business remains efficient and compliant.
Governance and Marketing Applications
Data Governance Practices
Strong data governance hinges on several key practices: conducting data protection impact assessments (DPIAs), implementing clear policies, assigning well-defined roles, and ensuring continuous monitoring. DPIAs are essential before deploying pseudonymisation methods, as they help evaluate whether these techniques effectively reduce re-identification risks and confirm that anonymisation removes all identifiers.
Role-based access controls play a crucial role in safeguarding sensitive data. Only authorised personnel should have access to pseudonymisation keys. For instance, marketing analysts can work with pseudonymised data to analyse campaigns without ever accessing re-identification details. Meanwhile, customer service teams may have limited access to re-identify specific records when assisting customers, but such actions must always be logged and audited.
Separating the storage of keys and data is another critical measure. The Data Protection Commission reports that organisations employing pseudonymisation in customer databases experience a 30–50% reduction in the severity of data breaches.
Ongoing monitoring of re-identification risks is equally important. Regular assessments ensure that pseudonymisation techniques remain robust against potential exploitation, as highlighted in GDPR Recital 26. Organisations must evaluate whether new data sources, analytics tools, or publicly available information could inadvertently enable re-identification when combined with pseudonymised datasets. Documenting these assessments and updating them as the data environment evolves is essential.
These governance strategies form the groundwork for using privacy-focused techniques in marketing while ensuring compliance and security.
Marketing Use Cases
Pseudonymisation and anonymisation offer distinct advantages for marketing. Pseudonymisation is particularly effective for customer profiling, tracking, and cross-channel analysis. By replacing email addresses or customer IDs with tokens, marketing teams can analyse behaviour patterns, monitor engagement across platforms, and build predictive models - all without exposing direct identifiers. For example, in January 2025, a European retail bank adopted tokenisation for customer identifiers in its Customer Data Platform (CDP). This move reduced the risk of exposing direct identifiers by 70% while enabling cross-channel campaign analysis and customer segmentation [EDPB Guidelines 01/2025].
GDPR Article 6(4)(e) provides an added benefit: pseudonymised data can be processed for purposes beyond its original collection, provided safeguards are in place. This allows businesses to repurpose transaction-collected data for behavioural analytics, predictive modelling, or new marketing initiatives without needing additional consent.
On the other hand, anonymisation is ideal for trend analysis and benchmarking, where individual identification is unnecessary. Fully anonymised datasets can be used to calculate metrics like conversion rates by emirate, average order values in AED, or funnel performance across segments. According to a 2023 IAPP survey, 68% of GDPR-compliant organisations utilise pseudonymisation in analytics and marketing systems, while 42% rely on anonymisation for trend reporting and benchmarking.
These applications highlight how proper governance enables businesses to extract actionable insights while maintaining compliance.
Wick's Approach to Privacy-Compliant Marketing

Wick integrates these privacy techniques into its Four Pillar Framework, focusing on the "Capture & Store" and "Tailor & Automate" pillars to ensure compliance and effectiveness.
Under the "Capture & Store" pillar, Wick consolidates customer insights using advanced data systems, such as behavioural tracking and customer journey mapping. By incorporating Customer Data Platform (CDP) solutions with built-in pseudonymisation, Wick protects client data while enabling strategic optimisation. For instance, during a CDP implementation for Baladna, Wick successfully secured over 1 million data points through tokenisation and encryption.
The "Tailor & Automate" pillar takes these efforts further by enabling AI-driven personalisation and automation systems that operate on pseudonymised data. This includes personalised email marketing, dynamic content delivery, and lead nurturing, all powered by tokenised identifiers. For broader reporting and benchmarking, Wick creates fully anonymised datasets by aggregating behavioural data and stripping all identifiers, aligning with GDPR's data minimisation principles.
Wick's integrated approach shows how governance, marketing applications, and strategic implementation can work together to achieve compliance while driving meaningful business outcomes.
Conclusion
Anonymisation and pseudonymisation serve as two powerful tools for safeguarding and using personal data responsibly. Anonymisation ensures complete removal of all identifiers, placing the data beyond the scope of GDPR. On the other hand, pseudonymisation substitutes identifiers with artificial tokens, retaining the possibility of re-identification through securely stored keys. This approach allows organisations to strike a balance between protecting privacy and maintaining the usefulness of data.
The upcoming EDPB guidelines, set for January 2025, highlight that while pseudonymisation isn’t a strict requirement, it strengthens GDPR compliance. By adopting these techniques, organisations align with the Privacy by Design principles outlined in Article 25, demonstrating to regulators that they’ve implemented robust technical and organisational safeguards. For businesses in the UAE catering to European clients, these measures are crucial for adhering to GDPR’s extraterritorial provisions.
Beyond regulatory compliance, these practices offer tangible advantages for both data protection and business insights. For instance, pseudonymisation allows marketing teams to study customer behaviour, build predictive models, and tailor campaigns - all without exposing sensitive personal details. Meanwhile, anonymisation is ideal for broader analysis, such as tracking trends or benchmarking, where individual identifiers aren’t necessary. This could include calculating conversion rates across emirates or analysing average order values in AED.
To effectively implement these measures, focus on three key actions: transform data using encryption or tokenisation, store decryption keys separately, and enforce stringent access controls.
FAQs
What is the difference between anonymization and pseudonymization under GDPR compliance?
Anonymization and pseudonymization are two important methods businesses use to safeguard personal data under GDPR regulations.
Anonymization means altering or removing information in a way that makes it impossible to identify individuals, even if the data is combined with other datasets. This process is permanent - once anonymized, the data cannot be traced back to any individual.
Pseudonymization, in contrast, replaces identifiable details with artificial identifiers or pseudonyms. While this provides an extra layer of privacy, the data can still be linked to individuals if additional, separately stored information is used. Under GDPR, pseudonymized data is still classified as personal data and must be handled with proper safeguards.
Both methods play a role in GDPR compliance, and the choice between them depends on your business's specific needs and the level of data protection required.
How can pseudonymization benefit UAE businesses managing EU customer data under GDPR?
Pseudonymization offers a practical solution for UAE businesses managing EU customer data, striking a balance between GDPR compliance and data usability. By replacing personal identifiers with unique codes or tokens, companies can significantly lower the chances of data breaches while safeguarding customer privacy. This method ensures that sensitive information remains shielded from unauthorised access, yet it still allows businesses to perform valuable analyses for operations or marketing.
For organisations in the UAE, pseudonymization becomes especially important when handling data that crosses international borders. It reflects a proactive stance on protecting personal information, strengthening trust with EU customers and partners. Adopting this approach signals a clear commitment to robust data protection and compliance with GDPR standards.
What steps can UAE businesses take to effectively implement pseudonymization techniques for GDPR compliance?
To implement pseudonymization effectively and meet GDPR standards, businesses in the UAE need to focus on converting personal data into a format that makes it impossible to directly identify individuals. This process typically involves substituting identifiable details with unique codes or tokens, while keeping the original data secure and stored separately.
Here’s how to approach it:
- Pinpoint sensitive information: Identify which personal data elements - like names, ID numbers, or contact details - require pseudonymization.
- Apply strong methods: Use techniques such as encryption, tokenization, or hashing to ensure the data is not easily traceable back to an individual.
- Protect key management: Store the mapping or decryption keys in a highly secure, access-restricted environment to prevent unauthorised use.
By following these steps, UAE businesses can minimise the risks of data breaches, maintain GDPR compliance, and build greater confidence in their data management practices.